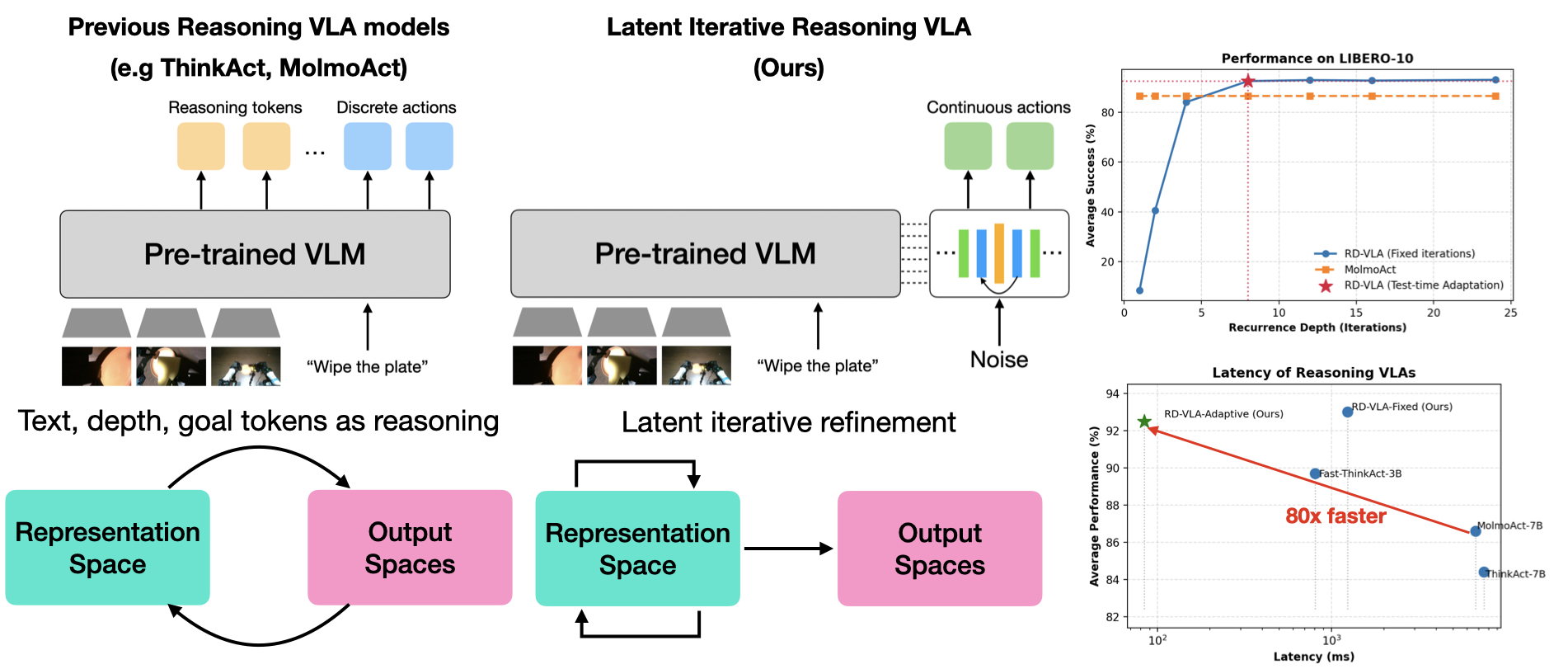
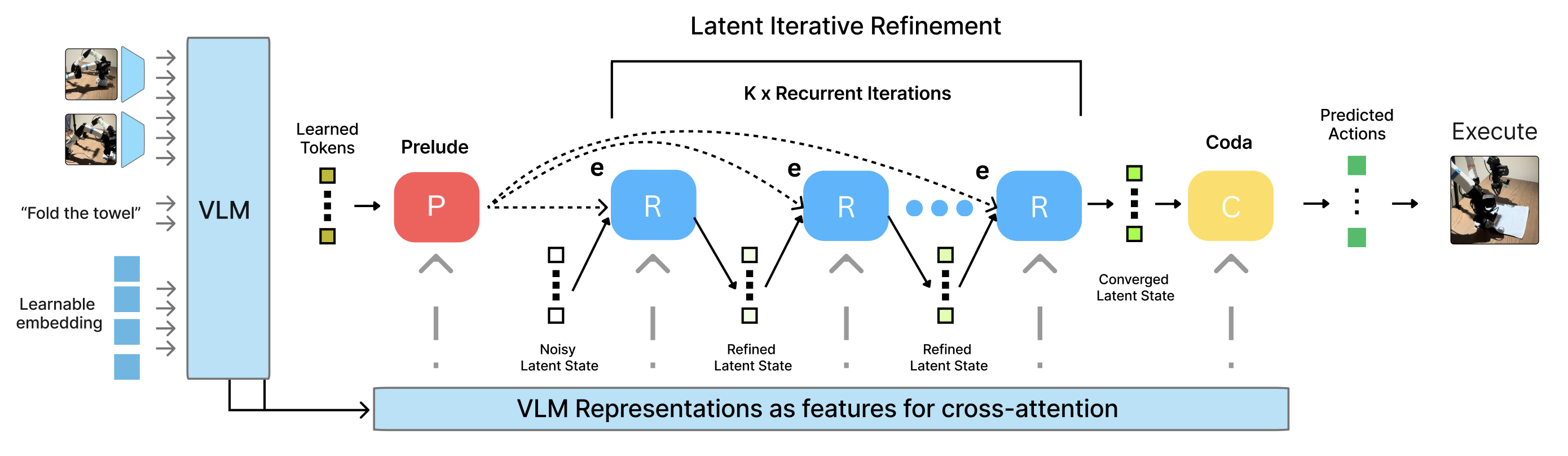
Current Vision-Language-Action (VLA) models utilize fixed computational depth, processing simple adjustments and complex multi-step manipulations with same amount of compute. While Chain-of-Thought (CoT) prompting enables variable compute, it scales memory linearly and struggles with continuous action spaces. We introduce Recurrent-Depth VLA (RD-VLA), an architecture that achieves computational adaptivity through latent iterative refinement instead of explicit token generation. RD-VLA employs a recurrent action head with weight-tied layers, enabling arbitrary depth with a constant memory footprint. We train the model using truncated backpropagation through time (TBPTT), allowing for efficient supervision of the refinement process. At inference, an adaptive stopping criterion based on latent convergence enables the model to dynamically allocate compute per sample. Our experiments on complex manipulation tasks demonstrate that recurrent depth is critical for success: tasks failing (0%) with single-iteration inference achieve +90% success with four iterations, while simpler tasks saturate quickly. RD-VLA provides a scalable path for test-time compute in robotics, bypassing the data and memory overhead of CoT while replacing discrete, token-based reasoning with latent reasoning, which maintains a constant memory footprint regardless of depth, and does not require any special data collection.
$$ ||\mathbf{a}_k - \mathbf{a}_{k-1}||^2_2 < \delta. $$
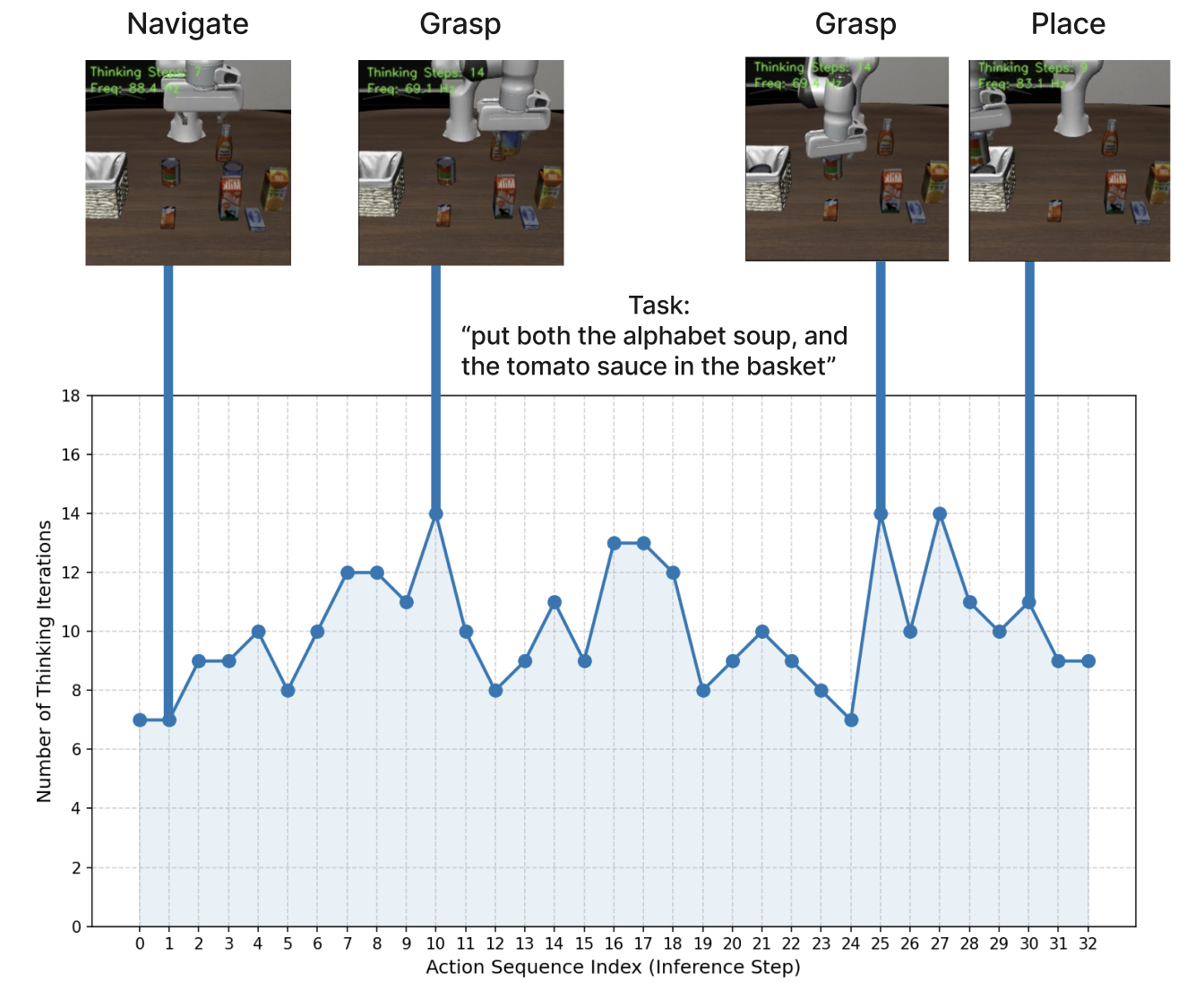
where ak is the predicted action chunk at step k and δ is a convergence threshold (e.g., 1e−3). This allows the model to self-regulate: terminating instantly for trivial movements while allocating extended compute for complex situations.Short-horizon Task
Long-horizon Task
Long-horizon Task (Failed)
@misc{tur2026rdvla,
title={Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning},
author={Yalcin Tur and Jalal Naghiyev and Haoquan Fang and Wei-Chuan Tsai and Jiafei Duan and Dieter Fox and Ranjay Krishna},
year={2026},
eprint={2602.07845},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.07845},
}